AI 메모리 6배 아끼는 구글 터보퀀트(TurboQuant)의 비밀: 득과 실 완벽 정리
AI 모델이 똑똑해질수록 우리 지갑은 얇아진다는 사실, 알고 계셨나요? 😅 안녕하세요, 원스입니다. 😊
요즘 챗GPT나 제미나이 같은 거대 언어 모델(LLM)을 돌릴 때 가장 큰 병목 현상은 바로 '메모리'입니다. AI가 대화 내용을 기억하기 위해 사용하는 KV 캐시(KV Cache)가 눈덩이처럼 불어나기 때문이죠. 오늘은 구글이 이 문제를 해결하기 위해 내놓은 야심작, '터보퀀트(TurboQuant)'에 대해 아주 쉽고 깊게 파헤쳐 보려고 합니다.
1. AI의 기억력 다이어트가 필요한 이유
우리가 AI와 긴 대화를 나눌 때, AI는 이전 대화 맥락을 모두 기억하고 있어야 합니다. 이 데이터를 저장하는 공간을 'KV 캐시'라고 부르는데, 이게 생각보다 엄청난 용량을 차지해요. 문장이 길어질수록 비싼 HBM(고대역폭 메모리)을 다 잡아먹어서, 결국 서비스 비용 상승의 주범이 됩니다.
- Llama-3 70B 모델 기준: 문맥이 길어지면 메모리 요구량 160GB 이상 발생
- HBM 부족 사태: 고성능 GPU를 써도 메모리 한계로 인해 동시 접속자 수 제한
- 기존 방식의 한계: 데이터를 단순히 반올림해서 줄이면(양자화) AI가 급격히 바보가 됨

2. 터보퀀트의 핵심: 극좌표계와 1비트의 마법
구글이 제안한 터보퀀트(TurboQuant)는 크게 두 가지 기술적 기둥으로 이루어져 있습니다. 바로 PolarQuant와 QJL입니다.
📍 PolarQuant: 숫자를 '각도'로 바꾸다
기존에는 숫자를 격자무늬(직교좌표계) 위에 올려두고 가까운 곳으로 반올림했습니다. 하지만 터보퀀트는 이를 '방향(각도)'과 '거리'로 표현하는 극좌표계로 옮깁니다. AI 데이터는 특정 방향으로 뭉치는 성질이 있는데, 이 성질을 이용해 방향성만 잘 보존해도 압축 효율이 어마어마하게 좋아지는 원리죠.
📍 QJL: 깎여나간 정확도를 되살리는 보정치
데이터를 너무 많이 압축하면 당연히 오차가 생기겠죠? 구글은 여기서 1비트짜리 보정 데이터를 살짝 추가하는 영리한 방법을 썼습니다. 아주 적은 용량만 추가했을 뿐인데, 압축으로 인해 발생한 오류를 획기적으로 줄여준 것이죠.
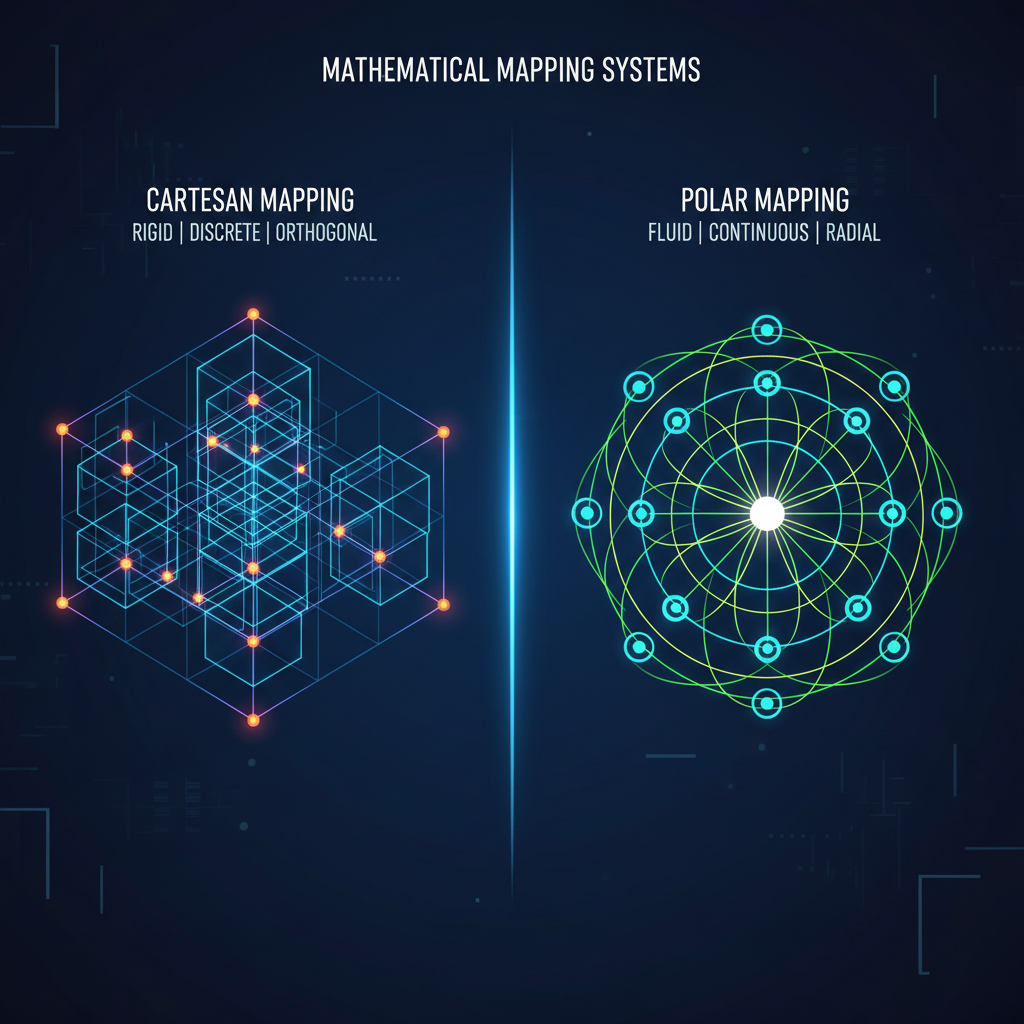
터보퀀트가 메모리를 6배 줄이고 속도를 8배 높였다는 결과는 정말 고무적입니다. 하지만 개발자이자 투자자의 관점에서 저는 한 가지 우려되는 지점이 있어요. 바로 '에러 프로퍼게이션(Error Propagation, 오차 전파)'입니다.
이번 실험 데이터는 비교적 작은 모델(Small models)에서 이루어졌습니다. 하지만 우리가 실제로 쓰는 수천억 개의 파라미터를 가진 초대형 모델(LLM)에서도 이 방식이 통할지는 의문입니다. 특히 최근 트렌드인 '추론형 AI(Reasoning)'는 한 단계의 실수가 다음 단계의 거대한 논리 오류로 이어집니다. 아주 미세한 압축 오차가 수만 개의 토큰을 거치며 눈덩이처럼 커진다면, 결국 AI가 헛소리를 하는 '할루시네이션' 현상이 심화될 수 있습니다.
결국 우리가 주목해야 할 포인트는 [압축률과 논리 보존의 황금비율]입니다. 단순히 메모리를 아끼는 것을 넘어, 하드웨어 단에서 이 복잡한 극좌표 계산을 얼마나 지연 시간(Latency) 없이 처리해내느냐가 상용화의 핵심이 될 것 같네요. 🤔
이웃님들은 AI의 속도와 정확도 중 무엇이 더 중요하다고 보시나요?
댓글로 자유롭게 의견 들려주세요! 👇
댓글
댓글 쓰기